There is an interesting paradox in context of developing data analysis software. On one side, there are clear benefits of designing tools that are easy to use, robust and require as little manual intervention or user expertise as possible. Such design philosophy allows more users to take advantage of the tools and apply them automatically to large heterogeneous datasets. On the other side, blindly applying tools that are not fully understood or do not provide useful information on whether the input data meets their assumptions can raise serious concerns. Developers take not only great pride in the quality of their software but also feel responsible for how the software is being used. Unexperienced users can misuse a “black box” tool and obtain misleading results. Whether we like it or not, such situations can lead to bad reputation misattributed to the tool itself.

Ease of use seems to be at odds with avoiding misuse. Extending your user base to less experienced users can lead to mistakes. Is there a way of designing “black box” tools that can minimize misuses? I believe there is - I call it the glass box philosophy.
It does not mean that developers must come up with their original content if such exists already. The purpose of educational documentation is that if the user wants to understand how a tool works they can learn about it from documentation in a programming language agnostic way.
 Documentation provided by the developers of FMRIPREP goes beyond the instruction how to use it. It includes a detailed explanation of the data processing workflow – together with figures and references to relevant literature. This rich documentation allows interested users to understand what happens to their data. The documentation does not rely on any knowledge of Python (which is the language FMRIPREP is written in).
Documentation provided by the developers of FMRIPREP goes beyond the instruction how to use it. It includes a detailed explanation of the data processing workflow – together with figures and references to relevant literature. This rich documentation allows interested users to understand what happens to their data. The documentation does not rely on any knowledge of Python (which is the language FMRIPREP is written in).

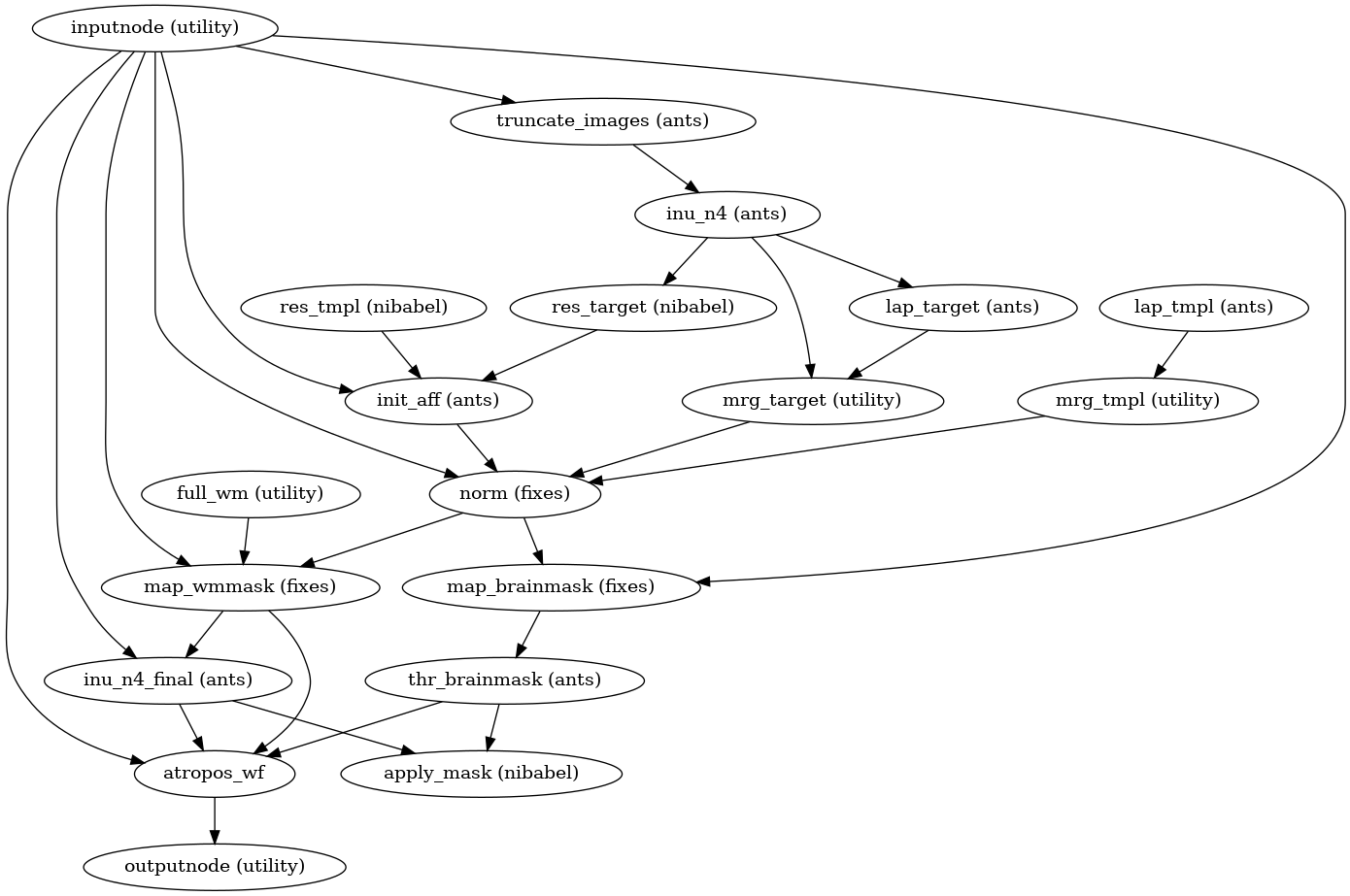
Preprocessing performed by FMRIPREP consist of many interdependent steps. Some of them cannot be validated in an automatic way which leads to a need for visual reports. For every processed piece of data, FMRIPREP produces an HTML report that includes figures and animations designed to highlight different data processing steps. Those reports enable users to quickly verify the validity of individual steps without the need to write any custom code or open intermediate results using specialized software.

FMRIPREP is targeted for research use, and thus its uses will most likely lead to scientific publications. One cannot assume that readers of those publications will be familiar with FMRIPREP, so there is a need to provide an abbreviated description of processing performed by FMRIPREP. The documentation website provides such boilerplate text ready to be reused in publications that used FMRIPREP. Because FMRIPREP runs the slightly different type of processing depending on the inputs, the boilerplate text can be easily adapted via JavaScript controls listing different input options.
Ease of use seems to be at odds with avoiding misuse. Extending your user base to less experienced users can lead to mistakes. Is there a way of designing “black box” tools that can minimize misuses? I believe there is - I call it the glass box philosophy.
The glass box principles
Write educational documentation
The documentation for a data analysis tool should aspire not only to describe how to run the tool but also to explain the theory and assumptions behind the analysis. In this, it should resemble more of an academic handbook than instruction manual.It does not mean that developers must come up with their original content if such exists already. The purpose of educational documentation is that if the user wants to understand how a tool works they can learn about it from documentation in a programming language agnostic way.
Verify or visualize assumptions
Most data analysis tools will consist of several steps each with their distinctive assumptions. If a step fails to produce expected results (in a silent way) it could have catastrophic consequences down the road. Unfortunately, in many cases, it is very hard or even impossible to programmatically verify if the results of a particular step meet quality requirements of the subsequent step. Thus, it is important that data analysis software provides an option to verify or visualize those assumptions. Such reporting capabilities might not be necessarily taken advantage by the user directly but can provide an extra layer of transparency. For example, more experienced users or reviewers of a paper describing the results could audit the reports generated by data analysis.Guide dissemination of the results
Obviously, the purpose of running a data analysis tool is to learn something about the data from the results. In clear majority of the cases, users will share the findings with people who were not involved in the analysis and might not know the details of the tool. Whether it is an internal report or an academic paper the user that runs the tool and obtained the result bears the responsibility of explaining to others what the analysis entailed. Here the tool developers can also help by providing boilerplate language summarizing the inner workings of the tool (referencing relevant external materials when possible). Peers of the user who performed the analysis will appreciate such feature because it allows them to understand better what exactly happened to the data. In case of robust tools that use heuristics to adapt to the input data, the boilerplate language should also automatically adapt to accurately describe the analysis path that was taken.FMRIPREP – an example of a glass box application
To better understand how a glass box application should look like let’s have a look at an example. FMRIPREP is an MR data preprocessing tool that takes whatever comes out of a magnetic resonance scanner and prepares it for higher level analysis. It was designed to adapt to a range of different scan types and use heuristics to provide quality results on a data produces by different scanners. The robustness and ease of use make it appealing to use, but also susceptible to misuse. So how does FMRIPREP implements the glass box principles?Educational documentation
Reports

Citation boilerplate

Cost
I hope I made a convincing argument for building robust, easy to use software that also excels in transparency. It is worth noting that the extra steps that need to be taken to turn a black box analysis tool into a glass box analysis tool require extra effort. After all guides for interpreting results and the educational documentation will not write itself and code for reporting tools will not appear out of anywhere. Nonetheless, I do feel that the glass box philosophy is worth pursuing and may reduce the amount of user support necessary for the analysis tool. Furthermore, some of the addition necessary to turn your app into a glass box (for example documentation) could be contributed by users themselves. This is a great opportunity to grow your open source contributor network.
PS I by no means invented the term “glass box” – it has been used previously (for example in the context of software testing). However, because this term fits so well with these design principles I decided to highjack it.
I wish to show thanks to you just for bailing me out of this particular trouble. As a result of checking through the net and meeting techniques that were not productive, I thought my life was done.chartered accountant firms in dubai
ReplyDeleteReaching towards the great services of box design to keep products protective. Although seeking the unique writing ideas with the report writers Malaysia for better academic success and make effective reports.
DeleteI totally get what you went through! It’s so frustrating trying to find real help online when everything seems confusing or unproductive. I had the same struggle until I found a trustworthy chartered accountant firm in Dubai — they really turned things around for me. It’s amazing how the right experts can make such a big difference!
DeleteMobile app development in Hyderabad
Perfect content, related to what is the best solution for business data backup , thanks!
ReplyDeleteNice Blog, Thanks for sharing
ReplyDeleteauditing company in uae
Thanks for sharing this, I actually appreciate you taking the time to share with everybody.
ReplyDeleteBest Institute For Data Science In Hyderabad
It is nice thing! Looks cool. Buy facebook likes for it from this page https://soclikes.com/
ReplyDeleteGreat post about python.
ReplyDeletepython course london
As always your articles do inspire me. Every single detail you have posted was great.
ReplyDeletecertification of data science
Hello there to everyone, here everybody is sharing such information, so it's fussy to see this webpage, and I used to visit this blog day by day
ReplyDeletedata science course in delhi
Very awesome!!! When I searched for this I found this website at the top of all blogs in search engines.
ReplyDeleteData Science Training in Hyderabad
Thanks for the information.
ReplyDeletedata scientist Course Institute
Great information, indeed!
ReplyDeleteInteresting article. AMCA is a leading audit firm in Dubai, UAE. We offer a variety of auditing & accounting services in Dubai. We are FTA approved tax agency.
ReplyDeleteThis article is amazing. It helped me a lot. keep up the good work. data science institute in delhi/ncr
ReplyDeleteI was basically inspecting through the web filtering for certain data and ran over your blog. I am flabbergasted by the data that you have on this blog. It shows how well you welcome this subject. Bookmarked this page, will return for extra. data science course in jaipur
ReplyDeleteReally Nice Information It's Very Helpful All courses Checkout Here.
ReplyDeleteai courses aurangabad
I have been searching to find a comfort or effective procedure to complete this process and I think this is the most suitable way to do it effectively.
ReplyDeletedata scientist training in malaysia
"Very Nice Blog!!!
ReplyDeletePlease have a look about "
data science training in chennai
Very interesting , good job and thanks for sharing such a good blog. we also provide glass software solutions. for more info visit our website.
ReplyDeleteLooking for all the latest styles of jackets 8 ball leather jacket and coats for men? Shop the best collection of men's jackets and coats. Free shipping available.
ReplyDeleteI want to say thanks to you. I have bookmark your site for future updates.
ReplyDeletedata scientist course in chennai
Thanks for these blog post . It is really amazing and having good knowledge about these post. I appreciate by seeing your work. glass software solutions.
ReplyDeleteVery good points you wrote here..Great stuff...I think you've made some truly interesting points.Keep up the good work.
ReplyDeletedata science course
tax consultants in dubai uae
ReplyDeleteIt has truly been an absolute pleasure visiting your site. It is a pleasure to have you on board and thanks for sharing your blog site with us - it is greatly appreciated.
ReplyDelete룰렛사이트탑
I was just examining through the web looking for certain information and ran over your blog.It shows how well you understand this subject. Bookmarked this page, will return for extra.
ReplyDeleteThanks for making the sincere attempt to explain this. I think very robust about it and want to learn more. If it’s OK, as you attain more extensive knowledge 온라인바카라
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteYes, I am entirely agreed with this article, and I just want say that this article is very helpful and enlightening. I also have some precious piece of concerned info !!!!!!Thanks. bitmain antminer s19
ReplyDeleteI really impressed after read this because of some quality work and informative thoughts . I just wanna say thanks for the writer and wish you all the best for coming Courtier immobilier Hull
ReplyDeleteI am hoping the same best effort from you in the future as well. In fact your creative writing skills has inspired me
ReplyDeleteRestaurant chair
Wow, this is really interesting reading. I am glad I found this and got to read it. Great job on this content. I like it
ReplyDeleteused motorcycles for sale
Thank you for another great article. Where else could anyone get that kind of information in such a perfect way of writing? I have a presentation next week, and I am on the look for such information polaris dealer
ReplyDeleteI am sure this post has touched all the internet viewers, its really really good paragraph on building up new webpage
ReplyDeletepolaris dealer
There are many dissertation internet sites on-line after you uncover unsurprisingly identified in your website page. ✅
ReplyDeleteantique display cabinet
I read a article under the same title some time ago, but this articles quality is much, much better. How you do this..
ReplyDeleteSkip Hire Ulverston
So lot to occur over your amazing blog. Your blog procures me a fantastic transaction of enjoyable.. Salubrious lot beside the scene
ReplyDeleteshipping from china
So lot to occur over your amazing blog. Your blog procures me a fantastic transaction of enjoyable.. Salubrious lot beside the scene
ReplyDeleteShipping To FBA Warehouse From China
I found so many interesting stuff in your blog especially its discussion. From the tons of comments on your articles, I guess I am not the only one having all the enjoyment here! keep up the good work. Compliance Services Malta
ReplyDeleteThis is such a great resource that you are providing and you give it away for free. I love seeing blog that understand the value. Im glad to have found this post as its such an interesting one! I am always on the lookout for quality posts and articles so i suppose im lucky to have found this! I hope you will be adding more in the future... Wordpress Malta
ReplyDeleteI am jovial you take pride in what you write. It makes you stand way out from many other writers that can not push high-quality content like you 토토사이트
ReplyDeleteThis is important, though it's necessary to help you head over to it weblink:
ReplyDelete출장홈타이
Very nice article, I enjoyed reading your post, very nice share, I want to twit this to my followers. Thanks!
ReplyDelete토토커뮤니티
I had been tiny bit acquainted of this your broadcast provided bright clear idea
ReplyDelete파워사다리
I had been tiny bit acquainted of this your broadcast provided bright clear idea 스마일도메인
ReplyDeleteI had been tiny bit acquainted of this your broadcast provided bright clear idea
ReplyDelete메이저사이트
"Excellent article. I’m going through many of these issues as well..
ReplyDelete" 토토사이트
I recently came across your blog and have been reading along. I thought I would leave my first comment. I don't know what to say except that I have enjoyed reading. Nice blog. I will keep visiting this blog very often. 토토솔루션
ReplyDelete360DigiTMG, the top-rated organisation among the most prestigious industries around the world, is an educational destination for those looking to pursue their dreams around the globe. The company is changing careers of many people through constant improvement, 360DigiTMG provides an outstanding learning experience and distinguishes itself from the pack. 360DigiTMG is a prominent global presence by offering world-class training. Its main office is in India and subsidiaries across Malaysia, USA, East Asia, Australia, Uk, Netherlands, and the Middle East.
ReplyDeleteI wish you possess a good health and well being.
ReplyDeleteCargo Services Dubai to Pakistan
Glass Works in Dubai
Thanks for sharing this. This would be a big help but I think writing an essay for college application
ReplyDeleteneeds only determination. If you are determined enough to enter college.
leather jacket
Wishing you the best of luck for all your blogging efforts.This is my first opportunity to chat this website
ReplyDeleteI found some interesting things and I will apply to the development of my blog.
wedding photography packages
Thanks you for sharing this unique useful information content with us. Really awesome work. keep on blogging
ReplyDeleteGlass companies in Nigeria
"My introduction to risotto was my mother's risotto Milanese," Tucci wrote, "but I have
ReplyDelete부산출장
I am happy to find your distinguished way of writing the post. Now you make it easy for me to understand and implement the concept. Thank you for the post. result totomacau
ReplyDelete
ReplyDeleteI learn from a good blog, your blog is a great inspiration, thank you. India visas for US citizens are available online. US citizens can apply for an Indian visa within 5 to 10 minutes. Firstly you can read all the document requirements for Indian visa for US citizens via our website then you can apply for your Indian visa.
This comment has been removed by the author.
ReplyDeletehttps://www.igotbiz.com/directory/listingdisplay.aspx?lid=192087
ReplyDeletehttps://www.jigsawplanet.com/ConnectFreelance?viewas=0255d69d5b78
https://bbpress.org/forums/profile/freelancevisadubai/
https://buddypress.org/members/freelancevisadubai/profile/
https://www.pixnet.net/pcard/91053621f564324939/article/e26ba240-e65f-11ec-a0e8-49c1d4c9968e?utm_source=PIXNET&utm_medium=pcard_article&utm_content=91053621f564324939
https://elearning.wmich.edu/d2l/lms/blog/view_userentry.d2l?ou=6606&ownerId=86384&entryId=407&ec=0&expCmd=1&sp=&gb=usr
https://www.blogger.com/profile/02911435215444306999
https://ameblo.jp/eddy900/entry-12747221132.html
https://linktr.ee/connectfreelance
Truly mind blowing blog went amazed with the subject they have developed the content. These kinds of posts are really helpful to gain the knowledge of unknown things which surely triggers to motivate and learn more. Travelers can obtain a Turkey visa from anywhere in the world. It is an electronic visa that can be obtained through the internet.
ReplyDeletehttps://www.vingle.net/posts/4588482
ReplyDeletehttps://c4c.tribe.so/post/the-advantages-of-hiring-a-payroll-service-in-the-uae-62cd69388f564cbc5bc412a6
https://roggle-delivery.tribe.so/post/the-trending-stuff-about-freelance-visa-62cd6fdd5e80e003b3242f1e
https://business-services-dubai.mystrikingly.com/
https://professionalservicesdubai.mystrikingly.com/
https://proexpert2112.tribe.so/post/steps-to-do-business-setup-in-dubai---explained-by-connect-me-62d15cf2ec1678b8482fde62
https://articlization.tribe.so/post/how-dubai-will-be-the-best-destination-for-business-setup-62d163fd799c7731564f7d15
https://legendarymedia.tribe.so/post/how-to-start-ecommerce-business-in-uae-emirates-62d1669dcad81e582f6a58a7
I truly adored visiting your post and this content was very unique. Thanks a lot for sharing this...
ReplyDeleteVirginia Spousal Support Calculator
Virginia Spousal Support
Great! It is interesting to read your blog, I appreciate your efforts. Thanks! best mens loung pants
ReplyDeleteAre you looking for a Property Buyers Agent Brisbane? Asset Plus Buyers Agents are your local experts with years of experience in the Brisbane property market. We can help you find the perfect property within your budget, and with all the features you're looking for. Contact us today to get started!
ReplyDeleteAre you looking for Trumpet Lessons in sydney, Australia? Standout Music Studio offers quality trumpet lessons for all levels, from beginners to advanced. Our trumpet teachers are experienced and passionate about music and will help you reach your musical goals. Contact us today to book a trumpet lesson!
ReplyDeleteAre you looking for a Townhouse Development in Melbourne, Australia? Bullseye Home Builders are the experts in a townhouse development. With many years of experience, we can help you design and build the perfect townhouse to suit your needs.
ReplyDeleteAre you looking for a teaching job in Delhi? Check out Teach India for the latest teaching job openings in Delhi. We have a wide range of jobs available for qualified and experienced teachers. Apply now and start your teaching career in Delhi today! Teach India Jobs In Delhi NCR
ReplyDeleteAre you looking for Sheer Curtains in Melbourne, Australia? Divine Interiors has a wide range of curtains to suit any home. We also offer custom-made curtains to ensure you get the perfect fit.
ReplyDeleteAre you looking for a Hacking Course in Hindi? Cyberpratibha offers the best hacking course in Hindi with 100% practical training. Learn from the experts and get real-world experience. Enrol now and get started today.
ReplyDeleteIn this article, you will get to know why the demand for data scientists has increased in the industry.
ReplyDelete360 DigiTMG Provides
best data science courses in hyderabad
Develop Magic is a Social Media Marketing Agency for Small Business in USA. Boost your online presence and reach your target audience effectively.
ReplyDeleteGrant Thornton is esteemed for its focus on mid-sized businesses. The firm provides audit, tax, and advisory services, offering tailored solutions and expertise to support the unique needs of growing enterprises in Dubai. best accounting firm in dubai
ReplyDeleteFascinating read on the Glass Box Design Philosophy! 🌐🔍 The concept of transparency, both in the literal and metaphorical sense, is truly groundbreaking. The emphasis on making the inner workings of a system visible not only promotes accountability but also fosters trust between creators and users.
ReplyDeleteYour breakdown of how the Glass Box approach encourages collaboration and open communication is eye-opening. It's a refreshing departure from traditional closed systems, and I can see how this philosophy aligns with the current trends in user-centric design.
I appreciate the real-world examples illustrating how companies are embracing the Glass Box approach to create more user-friendly and ethical products. The idea that informed users make better decisions is powerful and aligns perfectly with the current shift towards transparency in various industries.
The Glass Box Design Philosophy seems like a breath of fresh air in an era where consumers crave authenticity and honesty. Thanks for shedding light on this innovative approach—it's something I'll definitely be exploring further! 🌈🔓 #DesignPhilosophy #TransparencyInTech
please check it my website : https://getbakeroo.com/
ReplyDeleteThank you for your feedback! I'm glad you found the breakdown of the Glass Box approach insightful. Indeed, the philosophy of transparency and open communication fosters collaboration and innovation, which are essential in today's fast-paced and user-centric design landscape. By embracing transparency and allowing stakeholders to see and understand the inner workings of a project, teams can build trust, encourage feedback, and ultimately create better products and experiences for users. If you have any more questions or need further clarification on the Glass Box approach or any other topic, feel free to ask!
When organizing a trade show in New York, ensuring the safety and security of exhibitors, attendees, and assets is paramount. Here's how to find reliable trade show security services:https://dahlcore.com/trade-show-security
WritingTree's PhD thesis writing services in India are a game-changer! Expert assistance and a commitment to excellence make them a reliable resource for scholars aiming for academic success. research paper writing services
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteTyekon Research is listed in the top 10 research paper writing services in India. We have teamed up with the top-rated research paper writers to provide India's best Research Paper Writing Services.
ReplyDeletehttps://tyekonresearch.com/research-paper-writing-service.php
This comment has been removed by the author.
ReplyDeleteThe article presents a plethora of useful information.3 bhk flats gwalior
ReplyDeleteNavigating the intricate legal landscape of Delhi, female lawyers play a pivotal role in advocating for justice and equality. With expertise in diverse legal fields, these formidable professionals provide comprehensive legal counsel and representation to clients, ensuring their rights are protected. Empathetic and assertive, they navigate complex cases with finesse, embodying resilience and determination in the face of challenges. From civil disputes to criminal defense, their dedication to delivering favorable outcomes underscores their commitment to serving the community. As pillars of justice, Female Lawyer In Delhi exemplify integrity, proficiency, and the unwavering pursuit of fairness.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteNice BLog, If you are a young woman aspiring to join the armed forces and serve the nation, Centurion Defence Academy is the best NDA coaching institute in India for you. Join Today!
ReplyDeleteThanks for sharing nice and valuable information, I was looking for it. Really appreciated. Also visit swiftmarthub.com/ for best Exploring Salesforce services in world
ReplyDelete"Great insight! What are some strategies you think could help balance ease of use with ensuring users understand the assumptions and limitations of the data analysis tools they are using? 🤔💡
ReplyDeleteBest Digital Marketing Company In Nellore, Andhra Pradesh, India.
https://nuevostech.com/about-us/
I've taken a good look at your blog and read it, which I really liked. Label Printing
ReplyDelete"LA Cafe in Rishikesh offers a serene escape with its tranquil ambiance and flavorful menu. From freshly brewed beverages to locally sourced dishes, it's a must-visit spot for relaxation and culinary delights."
ReplyDelete'LA cafe in rishikesh ''
Thanks for this information
ReplyDeleteOnline medical courses
"Welcome to Little Amsterdam Rishikesh, nestled in the heart of Tapovan, Rishikesh, a hidden gem awaiting discovery. Since 2012, our quaint establishment has been a cherished spot for locals and travelers alike. Situated just 800m from Ram Jhula and 900m from Laxman Jhula, our location offers a breathtaking view of the majestic Ganga, adding to the serene ambiance of this spiritual town.
ReplyDeleteStep into our oasis and experience the warmth of our hospitality. Little Amsterdam Rishikesh is not just a bar and non-veg haven; it's a sanctuary for those seeking authentic experiences. Savor a diverse range of cuisines at our multi-cuisine restaurant or unwind with a selection of beers, whiskeys, and sheesha at our Ganga-view restaurant.
Why should you visit? Little Amsterdam Rishikesh isn't just a destination; it's an experience. Immerse yourself in the tranquility of Rishikesh's natural beauty while indulging in delectable dishes and refreshing beverages. Whether you're on a spiritual journey, seeking adventure, or simply looking to unwind, our establishment promises to be a highlight on your must-visit list of Tapovan Rishikesh.
Come, discover the 'Goa of Rishikesh' at Little Amsterdam Rishikesh, where every moment is infused with magic and memories are made to cherish.
"
"LA Cafe in Rishikesh offers a serene escape with its tranquil ambiance and flavorful menu. From freshly brewed beverages to locally sourced dishes, it's a must-visit spot for relaxation and culinary delights."
'LA cafe in Rishikesh ''
Your expertise in this field is evident in every post, and I appreciate the effort you put into creating high-quality content that is both informative and engaging. Luxury villas with pools in Gwalior
ReplyDeleteThe Glass Box Design Philosophy is all about transparency, simplicity, and clarity in product design. It focuses on creating structures where the inner workings are as visible and accessible as the external appearance. Design
ReplyDeleteFantastic post! Really appreciated the clarity and insights you provided. Looking forward to more of your content! Here we will learn how to fix 123.hp.setup error easily. Defeat your problems with our expert team. I highly recommend reaching out to HP Printer Support Pro.
ReplyDeleteContact us for professional assistance! Read 123.hp.setup blog for further support.
The glass box design philosophy is such an intriguing concept! It beautifully emphasizes transparency and openness, both in aesthetics and functionality. This approach not only allows for natural light to flood spaces but also fosters a sense of connection between the interior and exterior environments.
ReplyDeleteKavya Fashion Products
ReplyDeleteVery good written information. It will be useful to anybody who employees it, as well as me. Keep doing what you are doing can't wait to read more posts.
amazing stuff thanx
Study Abroad with the Best Overseas Education Consultants in Hyderabad
That's a lovely post, have a look at mine. Printed vs. Embroidered: How to Choose the Perfect Formal Dress for You
ReplyDeleteThat's a lovely post, have a look at mine. The Role of Coworking Spaces in Promoting Sustainable Development
ReplyDeleteAs a leading third-party service provider, we specialise in addressing issues such as account login failures, email delivery discrepancies, and concerns regarding security and privacy.You just have to simply Reach
ReplyDeleteWe can assist you with your queries without any delay.We are available 24/7 for our customers and provide knowledgeable advice. Expert advice to your Bigpond-related issues. We also provide 24/7 email support of Bigpond-related issues. Our representative tried to resolve all kinds of email’s errors And resume your service immediately.
Simply dial up Bigpond Phone number Australia +61-180-059-2260 to resolve any tech and not tech issues related to Bigpond.we abilene 24 Hours 7 Days Available.
Discover the handcrafted Black Cloud Party Shirt featuring eye-catching embroidery. Made from 98% cotton and 2% elastane, this versatile shirt is perfect for New Year’s Eve parties or casual gatherings. Pair it with jeans or chinos for a stylish look!
ReplyDeleteBook your Appointment - 93199 39500 / https://www.adityasachdevamen.in/products/party-shirt
Content Writer & SEO - Jai
All right reserved – Aditya Sachdeva Men https://www.adityasachdevamen.in
Thank you for sharing the wonderful information
ReplyDeleteoverseas insurance
Thank you for sharing the wonderful information
ReplyDeletenon-surgical shoulder pain treatment in Hyderabad
Thank you for sharing the wonderful information
ReplyDeleteknee and hip replacement center in Hyderabad
Thank you for sharing the wonderful information
ReplyDeletebest health insurance worldwide
Thank you for sharing the wonderful information
ReplyDeletesports injury treatment center in Hyderabad
Swinburne University students have challenging academic tasks, but with the right guidance, they can overcome giant battles. Whatever you need assistance with, be it essays, case studies, research papers, or technical assignments, The Tutors Help is here to make you a success.
ReplyDeleteDon't let homework chase you at night—call The Tutors Help today and enjoy improved grades and a successful learning experience!
https://www.thetutorshelp.com/swinburne-university-assignment-help.php
Swinburne University Assignment Help
Macquarie University is excellent at providing education, but assignment work is stressful. Don't wait until it's too late to worry about deadlines, research, or even formatting worries from The Tutors Help. Our expert writers make sure your assignments are of the highest academic standards and that you achieve top grades.
ReplyDeleteTherefore, if you require help with Macquarie University assignments, don't hesitate to contact The Tutors Help today and simplify university life!
https://www.thetutorshelp.com/macquarie-university-assignment-help.php
Macquarie University Assignment Help
This comment has been removed by the author.
ReplyDeleteExperts in heating, cooling, and ventilation, HVAC Services in North Miami offer reliable AC installation, repair, and maintenance for homes and businesses, ensuring optimal indoor comfort.
ReplyDeleteIf you are a student in Austria and struggling to finish your work, worry not. The Tutors Help is here to assist you step by step. If you need assistance in the area of research, writing, or even editing, our experts can be capable of assisting you.
ReplyDeleteWe will assist you in saving time, lowering stress levels, and enhancing academic performance. Chat with The Tutors Assistance today and receive the perfect assignment assistance in Austria!
https://www.thetutorshelp.com/edu/assignment-help-in-austria.php
Assignment Help in Austria
Assignments are part of your learning, and they ought not to be scary. You are a Georgia student, and you can leverage our professional help to enhance your writing. You might be struggling to write, need editing assistance, or stuck on a topic that matters but is complex, and we are here to help you.
ReplyDeleteDon't wait till the eleventh hour. Chat with the The Tutors Help today for the best assignment assistance in Georgia and simplify your academic life!
https://www.thetutorshelp.com/edu/assignment-help-in-georgia.php
Assignment Help in Georgia
I would like to sincerely thank you for sharing such valuable insights on this topic. Your content was not only informative but also very well-structured and easy to understand. It's great to see professionals like you contribute helpful resources to the industry. Looking forward to reading more from your blog! Apart from that, if you need any kind of information or services related to claims processing software, you can contact DataGenix. They provide the best and affordable services.
ReplyDeleteVery interesting to read this article.
ReplyDeleteupcoming government projects in Shamshabad
Best Drupal SEO Services to Boost Your Website Visibility
ReplyDeleteThanks for sharing this blog its really nice and clear Skinny Jeans
ReplyDeleteHi, my name is Avlok. Great blog post! I love how you explained everything so clearly. Definitely looking forward to reading more of your content!
ReplyDeleteYou made some excellent points here. Fantastic stuff... You've raised some rather intriguing arguments, in my opinion. Continue your excellent work Coffee Machine
ReplyDeleteReally thought-provoking post! The glass box design philosophy offers a refreshing perspective on transparency and user experience. While searching for a tally institute near me to upgrade my accounting skills, I’ve also become more interested in how design influences trust—this article connected the dots nicely.
ReplyDeleteYour blog is truly outstanding, offering clear and valuable insights that make complex topics easy to understand. The engaging content keeps readers hooked and informed. Thank you for sharing such high-quality information! For those interested in claims processing software, contact DataGenix, a leader in the medical claims industry. Their affordable, innovative solutions simplify healthcare claims management for payors and TPAs.
ReplyDeleteGreat insights on financial management! In today’s fast-paced business environment, Virtual CFO Services are proving to be a game-changer—especially for startups and SMEs looking for strategic financial guidance without the cost of hiring a full-time CFO. These services help businesses improve cash flow, budgeting, forecasting, and compliance while staying lean and agile. Thanks for sharing such valuable information—looking forward to more content like this!
ReplyDeleteInteresting perspective on the glass box design philosophy—transparency in systems definitely builds trust. It reminds me how crucial clear, accessible information is in all fields, even in healthcare, where people often search for safe options like where to buy abortion pills online. Thanks for sharing this!
ReplyDeleteThanks for share this great and informative article with us.
ReplyDeleteVulnerability management services in California
Great Blog,
ReplyDeleteDesignogram helps you boost your Business.
As a digital marketing agency, we strive to understand our client’s business goals first. Then all decisions are made with those goals in mind. A shiny new website is worthless if it doesn’t help you reach your goals. You talk, we listen… then we throw in lots of ideas for improvement. Not every Digital Marketing Agency is created equal. At Designogram, we know that the best results come from having the right people working on the right project. Our experienced team offers expertise in various areas of Digital Marketing Agency services, which is why each client is matched with a suitable group of experts to help them achieve their goals. With our proven strategies, your business is bound for wild success.
Social Media Marketing Agency in Ludhiana
Digital Marketing in Ludhiana
Social Media Marketing in Punjab
We specialize in offering a wide range of exciting travel packagesTour and Travel Company in Delhi tailored to meet your unique preferences and needs. Whether you're planning a family vacation, a romantic getaway, or an adventurous trip, our team is dedicated to providing you with the best travel experiences.
ReplyDeleteInteresting read! By the way, if anyone’s looking into higher education options, exploring the top 10 university in delhi can be a great start. The region offers top institutions with strong academics and career support.
ReplyDeleteThank you for this insightful exploration of the Glass Box Design Philosophy. At College Laundry, we are committed to providing transparent and user-friendly solutions to our clients. The principles outlined, such as writing educational documentation, verifying assumptions, and guiding the dissemination of results, resonate deeply with our approach to service design. Implementing these practices ensures that our users not only benefit from our services but also understand the processes behind them, fostering trust and satisfaction.
ReplyDeleteThis is a fascinating concept! The Glass Box Design Philosophy beautifully emphasizes transparency, clarity, and Adobe openness in design principles that are both visually striking and user-centric.
ReplyDeleteJual titanium batangan
ReplyDeleteTITANIUM BATANGAN / BARS / RODS
Kami menjual Round Titanium Batangan produk sesuai ASTM B348/ASME SB348 tersedia di Grades 1, 2, 3, 4, Gr5 (Ti6AL4V) dan nilai titanium lainnya in round bars sizes up to 500 diameter, rectangular and square sizes are also available. Kami menyediakan AMS 4928, AMS 4911, AMS 2631, AMS 4901, AMS 4907, AMS 4919, AMS 6931, AMS T 9046, AMS T 9047, ASTM B 337, ASTM B 338, ASTM B 381, ASTM F 67, ASTM F 136, ASTM B 348, ASTM B265 dan pipa, fittings & flanges with NORSOK M630 Rev 2 MDS T01 specifications for North sea petroleum industry developments dan operations dengan sangat harga murah.
See more Info": https://titanium.co.id/titanium-bars-rods/
Simplify complex nonprofit processes with Melonleaf. Our Salesforce Nonprofit Cloud Services support smarter decision-making, impact measurement, and enhanced transparency across teams.
ReplyDeleteSalesforce Nonprofit Cloud implementation
Infozion is where your growth starts!
ReplyDeleteFind the best EUROPESNUS ICEBERG deals and enjoy savings.
ReplyDeleteThe limited Iceberg Pie Collection combines bold flavors with signature Iceberg intensity.
ReplyDeleteUnlock unbeatable SNUS deals with your SNUSCORE Discount membership.
ReplyDelete"Your work in promoting open science and advancing neuroimaging tools is truly inspiring. I really appreciate how you explain complex research concepts with clarity and purpose. Posts like these make cutting-edge science more accessible and encourage collaboration across the field. Thank you for sharing your knowledge!"
ReplyDeleteWe offer a comprehensive and well-structured Abacus syllabus and Vedic Maths syllabus designed to enhance your child's mental calculation, concentration & speed
visit abacustrainer
Book your dream cruise today with Luxury Cruise Trips and enjoy up to 20% OFF on your first booking!
ReplyDeleteExplore breathtaking destinations, world-class service, and unforgettable luxury—all at an unbeatable price.
Visit Website: www.luxurycruisetrips.com
System conflicts, registry problems, or corrupted installation files are the most common causes of QuickBooks Error 80010. Update QuickBooks, launch the QuickBooks Tool Hub, and, if necessary, do a clean install to resolve it step-by-step. Additionally, make sure QuickBooks activities aren't being blocked by security settings and that your Windows system is up to date.
ReplyDeletehttps://proadvisorsupport.com/blog-details/rectifying-quickbooks-error-80010-cant-send-payroll-data
This site is optimize
ReplyDeleteHerbal veterinary supplements
High quality calcium supplement
This is a fantastic post! It really made me think about
ReplyDeleteOur Software Testing Course in Belapur is tailored to equip students with the skills needed to excel in the tech industry. We offer specialized industrial training, especially beneficial for individuals with a 2-3 year career gap, providing them with a structured pathway back into the field. The course includes hands-on experience through live projects, ensuring practical, job-ready skills. Additionally, participants receive an experience letter, ISO certification, and 100% placement assistance to enhance employability. Our training is both practical and job-oriented, with options for individual training (one faculty per student) to ensure personalized guidance. A free demo session is available for interested learners, allowing them to explore our teaching methods and course structure before committing. For more Information :- https://cncwebworld.com/mumbai/software-testing-course-in-belapur.php
ReplyDeleteWe are providing Online/Offline all IT trainings. Industrial training for who has gap around 2-3 year we will replace in industrial training .provide live projects and experience letter. We offer specialized industrial training, especially beneficial for individuals with a 2-3 year career gap, providing them with a structured pathway back into the field. The course includes hands-on experience through live projects, ensuring practical, job-ready skills. Additionally, participants receive an experience letter, ISO certification, and 100% placement assistance to enhance employability. Our training is both practical and job-oriented, with options for individual training (one faculty per student) to ensure personalized guidance. A free demo session is available for interested learners, allowing them to explore our teaching methods and course structure before committing. For More Information Visit :- https://cncwebworld.com/
ReplyDeleteWant to grow your small business online? Explore our latest blog on Digital Marketing Company for Small Business to learn effective strategies, expert tips, and proven techniques to boost visibility and drive sales in today’s competitive market.
ReplyDeleteThank you for compiling such informative Information. It has been very helpful.
ReplyDeleteMidinnings - Hospitality Marketing Company in Udaipur, India
FACEBOOK- https://www.facebook.com/Midinnings
LINKDIN- https://www.linkedin.com/company/midinnings
INSTAGRAM-https://www.instagram.com/midinnings/
YOUTUBE-https://www.youtube.com/@midinnings
Thank you for the helpful blog, "The glass box design philosophy." I want you to know that your information is invaluable for aspiring candidates. Keep sharing valuable updates!
ReplyDeleteNeet World Coaching Institute in Narayanguda, Hyderabad
I recently came across this Digital Marketing Institute in Noida, and I must say it’s one of the best places for anyone who wants to build a strong career in digital marketing. The trainers are highly experienced, the course modules are updated as per industry standards, and the practical exposure is excellent. From SEO, SEM, and social media marketing to advanced tools and strategies, everything is covered in detail.
ReplyDeleteGreat read! The glass box idea really connects with how companies offering Accounting Services in Dubai are focusing on transparency and trust today.
ReplyDeleteThank you for the helpful blog, "The glass box design philosophy." I want you to know that your information is invaluable for aspiring candidates. Keep sharing valuable updates!
ReplyDeleteChandu Biology Classes
The article suggests making data tools easy to use and transparent. The "glass box" approach helps prevent misuse by providing clear documentation, visual checklists, and summaries. fMRIPrep is a good example of this. Angel Web Technology
ReplyDeleteThe AI-centric revolution: Navigating the next software frontier
ReplyDeleteObtaining a Factory Registration Certificate is essential for ensuring compliance under the Factories Act. It safeguards worker welfare and validates that your manufacturing unit operates within legal safety standards. Agile Regulatory simplifies the entire registration process, assisting businesses with documentation, approvals, and renewals to ensure smooth and compliant factory operations.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteVery well explained! Cloud ERP is transforming how businesses operate by enabling remote access, automation, and smart inventory management. An experienced ERP Service Provider can help businesses implement ERP effectively with customization, support, and integration.
ReplyDeleteThis article gives valuable insights into the tyre-recycling-business-in-india, especially for new entrepreneurs exploring sustainable ventures. Proper compliance and licenses are essential for smooth operations. For assistance with regulatory approvals and environmental certifications, you can check Agile Regulatory for expert support.
ReplyDeleteGreat post! I really enjoyed reading this and found the information both insightful and easy to understand. The way you explained the topic makes it helpful for readers Dell Printer Setup at all levels, and the flow of the content keeps it engaging from start to finish.
ReplyDeleteThank you for sharing this detailed and informative article. The explanations are clear, and the content feels practical rather than theoretical. I found several points that I can apply immediately. Keep publishing such quality posts; they truly help readers learn something new. California Lottery Winning Numbers
ReplyDeleteThanks for sharing such informative information – it was a valuable article. By the way, to take part in the McDonald’s survey or win rewards, go to the mcdvoice.com survey.
ReplyDeletehanks for sharing such helpful and informative content. It was truly worth reading. By the way, to participate in the McDonald’s survey and earn rewards, visit the www.mcdvoice.com survey.
ReplyDeleteReading this article was a pleasant experience. The tone was friendly and professional, and the points were explained in a way that made sense. I especially liked how the post focused on practical understanding rather than just theory. Looking forward to reading more posts like this. tellculvers.com survey code
ReplyDelete🌟 Top Astrologers in the World (Widely Known)
ReplyDelete🌍 Internationally Recognized
• Bejan Daruwalla (India) – One of the most famous astrologers globally; known for newspaper predictions and mass appeal.
• Susan Miller (USA) – World-renowned astrologer; founder of Astrology Zone.
• Dr. Sundeep Kochar (USA) – Legendary astrologer and bestselling author (classical influence).
• Chani Nicholas (Canada/USA) – Modern astrologer with a global following.
🇮🇳 Top Astrologers in India
• Dr. Sohini Sastri – Award-winning astrologer; known for Vedic astrology and vastu.
• Pt. Sanjay Rath – Highly respected Vedic astrologer and teacher.
• K.N. Rao – Legendary authority on Vedic astrology and research.
• Dr. Sundeep Kochar – Well-known media astrologer and vastu expert.
🔮 How “Top Astrologer” Is Usually Defined
A top astrologer is judged by:
• Years of experience
• Accuracy of predictions
• Knowledge of Vedic / Western astrology
• Client trust & global reach
• Media presence or published work.
https://www.sundeepkochar.com/
Thanks for this insightful post! It was a great read. By the way, for those who are music enthusiasts like me, don’t forget to pair your devices seamlessly using spotify.com pair—it makes streaming so much easier!
ReplyDelete"Looking for a laptop for rental in Bangalore? 💻
ReplyDeleteWe offer reliable and high-performance laptops on rent for students, working professionals, startups, and corporates. Choose flexible rental plans with affordable pricing, quick delivery, and dedicated technical support. Ideal for training programs, office work, short-term projects, and remote working needs.
laptop for rental in bangalore "
Thanks for this blog! You explained everything in a simple and engaging way. By the way, I’m a big fan of 247 mahjong solitaire, and this content was truly useful.
ReplyDeleteI truly appreciate this well-explained content. Anyone who has recently visited McDonald’s should take a moment to fill out the mcdvoice.com survey and help improve their overall experience.
ReplyDelete" href="https://webxtalk.com/">Webxtalk is one of the top digital marketing businesses in India because to the effective implementation of an SEO strategy that focuses on results. We have effectively incorporated marketing automation into a number of initiatives.
ReplyDeletewebxtalk
ReplyDeleteAdvanced casino api provider india supporting multiple games with real time updates and secure integration features
ReplyDeletecasino api provider india
casino api provider india
casino api provider india
casino api provider india
The 11six24 discount code is perfect for bargain hunters looking to maximize value without compromising on quality.
ReplyDeleteVery informative article on Sports Betting API Integration Services. I liked the way you explained real-time data integration and platform scalability.
ReplyDeleteSports Betting API Integration Services
Sports Betting API Integration Services
best Sports Betting API Integration Services
best Sports Betting API Integration Services
Unlock incredible savings on pickleball gear with our exclusive Pickleball Discount Code. Perfect for paddles, balls, and apparel, this code makes upgrading your game both affordable and exciting.
ReplyDeleteEnter our Pickleball Discount Code during checkout to unlock discounts on paddles, balls, apparel, and everything you need for the court.
ReplyDeleteEnhance your pickleball experience affordably. Our Pickleball Discount Code provides discounts on everything from paddles to apparel, helping you play smarter and save money every time you shop.
ReplyDeleteDon’t let high prices slow you down! Use our Pickleball Discount Code for amazing deals on quality equipment and apparel, so you can focus on improving your game without worry.
ReplyDeleteSearching for affordable pickleball gear? Use our Pickleball Discount Code at checkout to enjoy special offers and discounts on top-quality equipment. Your next game just got more rewarding.
ReplyDeleteUpgrade your pickleball gear today! Apply our Pickleball Discount Code to enjoy savings on high-quality paddles, shoes, and accessories. Great deals make improving your game even more fun.
ReplyDeleteEnjoy premium pickleball equipment for less! Our Pickleball Coupon Code helps you get amazing deals on gear, accessories, and apparel so that you can play harder while spending smarter.
ReplyDeleteShopping for pickleball essentials? Don’t forget to use our Pickleball Code at checkout. You’ll score great savings while enjoying top-quality equipment designed for all skill levels.
ReplyDeleteDiscover unbeatable savings with our Pickleball Promo Code. From high-performance paddles to stylish gear, this code ensures you get the best deals without compromising your pickleball experience.
ReplyDeletePickleball lovers, rejoice! Our Pickleball Buy Code lets you save on high-quality gear, ensuring your equipment is as competitive as your game without stretching your wallet.
ReplyDeleteSave big while enjoying pickleball! Our Pickleball Purchase Code grants exclusive deals on gear and apparel, making it easier than ever to enjoy your favorite sport without overspending.
ReplyDeleteWant premium pickleball gear for less? Apply our Pickleball Discount Code at checkout to unlock fantastic savings on paddles, balls, and accessories for players of all levels and ages.
ReplyDeleteMaximize your pickleball budget with our exclusive discount code. From beginner paddles to professional gear, this Pickleball Discount Code ensures you pay less while playing your best.
ReplyDeletePickleball enthusiasts rejoice! Our Pickleball Discount Code offers unbeatable deals on gear and accessories, letting you enjoy your favorite sport while keeping your wallet happy and satisfied.
ReplyDeleteSave more every time you shop for pickleball gear. With our Pickleball Discount Code, you can access exclusive offers on paddles, nets, and apparel without sacrificing quality or style.
ReplyDeletePickleball just got more affordable! Redeem our Pickleball Savings Code for exciting discounts on paddles, balls, and apparel. Save money while enjoying your favorite sport with superior gear.
ReplyDeleteGet ready for the court with amazing savings! Use our Pickleball Discount Code to enjoy special discounts on equipment and accessories, making your pickleball experience both fun and budget-friendly.
ReplyDeleteStep up your pickleball game without overspending. Apply our Pickleball Offer Code to access exclusive discounts on paddles, shoes, and apparel designed for players of every skill level.
ReplyDeleteTake your pickleball skills to the next level without overspending. Apply our Pickleball Buying Code to save money on paddles, shoes, and accessories while keeping your game strong.
ReplyDeleteMake every pickleball purchase count. Enter our Pickleball Discount Code to receive special offers on paddles, balls, and apparel, helping you elevate your game at a fraction of the cost.
ReplyDelete
ReplyDeleteDiscover our 2.5 MM high-quality copper wire by TWC Advance. Ideal for reliable electrical connections, durable, and efficient. Perfect for professional and industrial use. Order now!
Book Your Order :- +91 9717243006 :- https://twcindia.co.in/blogs/twc/2-5-mm-high-quality-copper-wire-twc-advance-premium-copper-wiring
Content Writer & SEO - Jai
All right reserved – TWC Advance Wire :- https://twcindia.co.in/
Thanks for sharing this insightful post! I especially liked the way you explained. It gave me a fresh perspective. I'll definately try to implement this in my https://ipdocketers.com/ip-docketing-scalable-legal-growth/
ReplyDeleteThanks for sharing this insightful post! I especially liked the way you explained. It gave me a fresh perspective. I'll definately try to implement this in my https://patentzoom.us/future-of-patent-law-ai-vs-patent-attorneys/
ReplyDeleteVery informative content on jili api game integration. Businesses looking to launch gaming platforms can benefit greatly from fast and secure API connectivity solutions.
ReplyDeletejili api game integration
jili api game integration
jili api game integration
jili api game integration
The XFL is a professional American football league that has undergone multiple iterations since its inception in 2001. Designed as a spring football league, it provides fans with exciting, fast-paced action during the NFL’s off-season.
ReplyDeleteThe United Football League (UFL) is the premier spring professional football league created from the 2023 merger of the USFL and XFL.
ReplyDeleteBuying sports tickets in 2026 has never been easier, thanks to the proliferation of online platforms offering convenience, transparency, and competitive pricing. From official team sites to large secondary marketplaces, choosing the right platform can save money, guarantee authenticity, and improve your overall fan experience.
ReplyDeleteChoosing a university with top-tier sports facilities is essential for student-athletes, sports enthusiasts, and those who enjoy world-class recreational amenities. In 2026, several U.S. universities stand out for their investment in training centers, stadiums, and multi-sport complexes.
ReplyDeleteDiscount sports apparel can be purchased from numerous online and physical retailers, offering affordable gear for athletes and fans alike. These stores provide deep discounts on popular brands like Nike, Under Armour, Adidas, and Champion. Many items are priced around $20-$40, making it easy to refresh your workout wardrobe or fan gear without breaking the bank.
ReplyDeleteFans can request free merchandise from sports teams through letters, emails, or online forms, receiving stickers, schedules, small gear, or promotional items, with patience and polite, genuine requests.
ReplyDeleteRunning effective sports marketing campaigns in the USA requires leveraging fan passion, emotional engagement, and strategic brand storytelling. Success depends on understanding your audience, creating shareable content, timing campaigns around live events, and partnering with athletes or teams.
ReplyDeleteNIL (Name, Image, Likeness) lets college athletes profit from endorsements, appearances, social media, and merchandise while maintaining eligibility, transforming amateurism into brand-driven opportunities with financial, legal, and recruiting implications.
ReplyDeleteSports Direct is the UK’s leading sports retailer, offering a dynamic environment for individuals passionate about sports, fitness, and customer service. Joining the company provides the opportunity to engage with top brands, assist customers in achieving their fitness goals, and contribute to the growth of a successful retail leader.
ReplyDeleteRedshirts in college sports are student-athletes who sit out official competition for a season to preserve eligibility, allowing development, injury recovery, academic adjustment, and strategic team planning while still practicing and training.
ReplyDeleteThe 2026 NHL Stanley Cup Playoffs began on April 18, 2026. The postseason is the final stage of the season in the National Hockey League. It brings together the best 16 teams competing for the championship trophy.
ReplyDelete